Spring中Bean的生成过程
先从整理看下,Bean的生成过程中都包含了哪些步骤。
生成BeanDefinition
合成BeanDefinition
加载类
实例化前
实例化
BeanDefinition的后置处理
实例化后
自动注入
处理属性
执行Aware
初始化前
初始化
初始化后
Bean生命周期流程图
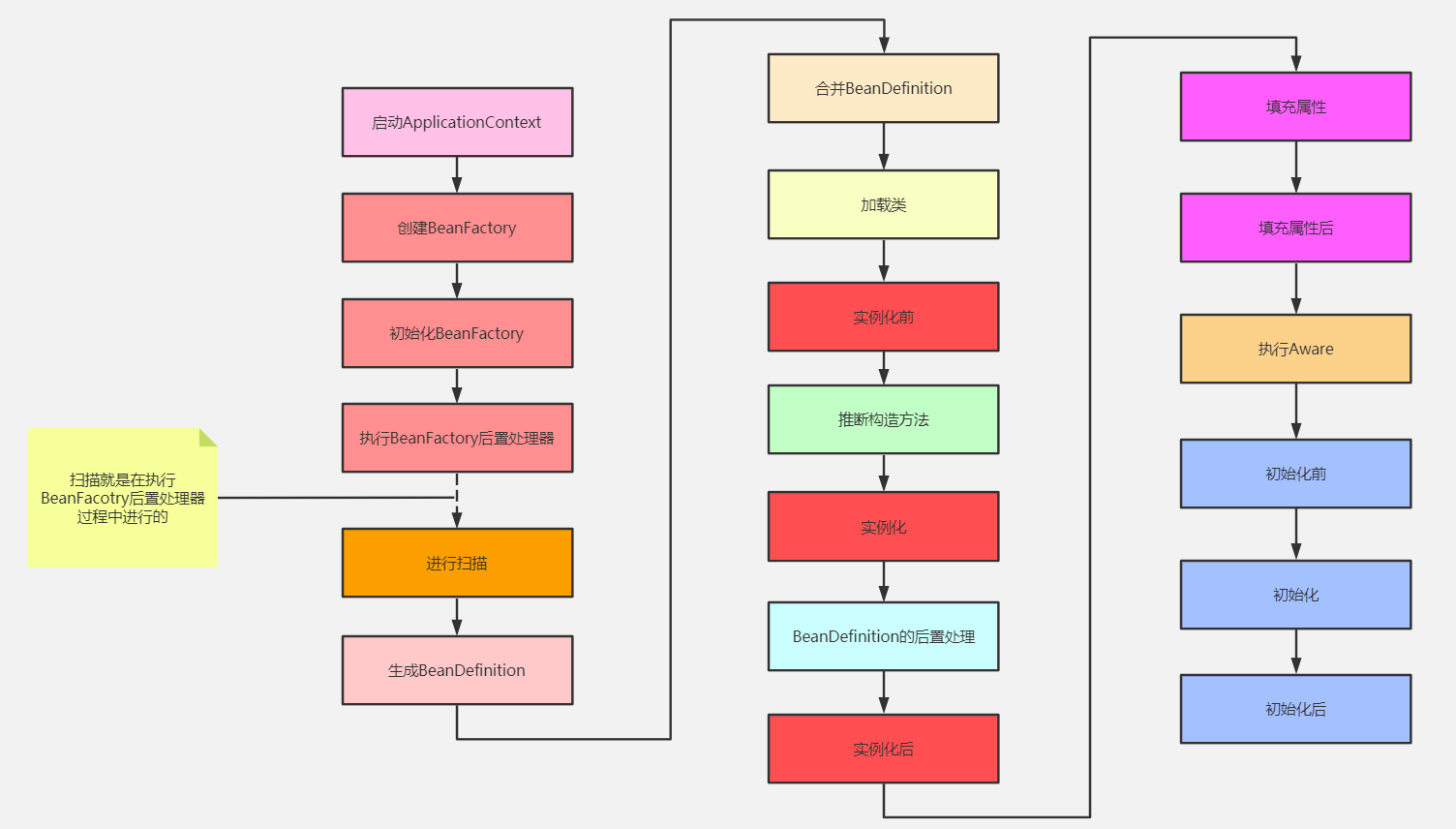
- InstantiationAwareBeanPostProcessor.postProcessBeforeinstantiation()
- 实例化
- MergedBeanDefinitionPostProcessor.postProcessMergedBeanDefinition()
- InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation(bean)
- 属性赋值(Spring自带的依赖注入)
- InstantiationAwareBeanPostProcessor.postProcessProperties(@Autowired)
- 初始化前
- 初始化
- 初始化后
首先我们了解到的,在Spring的启动过程中,针对bean的处理主要做了两个方面的
- 扫描指定路径
- 实例化bean(此处的实例化准确的说是实例化非懒加载的单例bean)。
那我们先来分析,Spring是如何去扫描路径、加载所需要的class文件。
从Spring启动过程来看,在refresh方法中,invokeBeanFactoryPostProcessors(beanFactory)中会调用Scanner.scan方法,进行bean的扫描,finishBeanFactoryInitialization中对扫描到的bean进行真正的实例化,完成bean工厂的初始化。
扫描
先看下扫描方法的调用栈信息
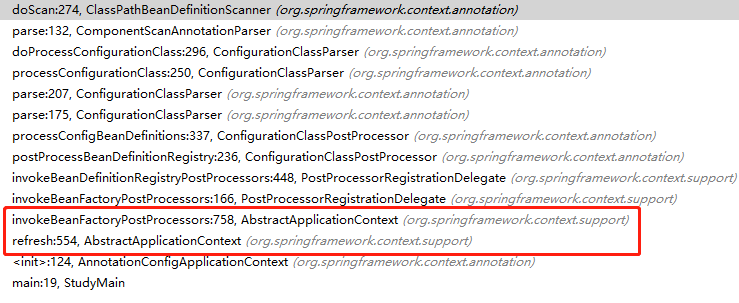
看代码
ClassPathScanningCandidateComponentProvider.scanCandidateComponents
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
|
这段代码中读取到了传入路径的所有class文件,并按照需要进行了路径处理。然后遍历所有文件,通过元数据读取器,遍历读取每一个文件的元数据信息,然后根据元数据信息判断当前类是否需要注册成为一个bean,最终返回。
在遍历元数据时,实现了excludeFilters和includeFilters判断,其中Conditional条件加载功能也在这块进行了实现,Conditional注解在我们实际使用中不多,但是在SpringBoot源码中使用的会很多。Conditional实现方式也很简单,创建一个类实现Condition接口,实现其中的matches方法,根据需要判断是否加载某个类就可以,在spring启动加载的时候,会根据某个类中是否添加了@Conditional,如果有则会调用注解中指明的类实现的matches方法。
源码中的位置在ConditionEvaluator.shouldSkip(@Nullable AnnotatedTypeMetadata metadata, @Nullable ConfigurationPhase phase),具体代码就不贴了,有兴趣的可以直接从源码中找到。
返回到上面的代码中,判断了当前class是一个bean之后,就开始创建beanDefinition,new 除 beanDefinition并做基本的属性赋值,然后又再一次判断了当前的bean是不是内部类、接口、抽象类、或者是(是一个抽象类,同时该类中具有被Lookup注解的方法),根据判断结果决定是否要将当前的类加入到最终返回的candidates对象中。
这样基本的BeanDefinition就完成了,在扫描过程中涉及到了Lookup注解的使用。但是到目前为止,beanDefinition中大部分属性还没有赋值,目前主要是保存了beanClass内容。
得到BeanDefinition的set集合后,接下来就需要遍历,然后对BeanDefinition中的属性进行赋值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
|
这个里面有一个细节,在生成beanName的时候,如果我们定义的BeanName名称首字母大写,且第二个字符小写的时候会将首字母小写作为默认的BeanName,但是如果第一个字母和第二个字母都是大写则不会处理。
例如:User —> user URL —> URL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
protected String buildDefaultBeanName(BeanDefinition definition) {
String beanClassName = definition.getBeanClassName();
Assert.state(beanClassName != null, "No bean class name set");
String shortClassName = ClassUtils.getShortName(beanClassName);
return Introspector.decapitalize(shortClassName);
}
public static String decapitalize(String name) {
if (name == null || name.length() == 0) {
return name;
}
if (name.length() > 1 && Character.isUpperCase(name.charAt(1)) &&
Character.isUpperCase(name.charAt(0))){
return name;
}
char chars[] = name.toCharArray();
chars[0] = Character.toLowerCase(chars[0]);
return new String(chars);
}
|
到这,所有的扫描工作就告一段落了。
生成BeanDefinition
Spring启动的时候会进行扫描,会先调用org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#scanCandidateComponents(String basePackage) 扫描某个包路径,并得到BeanDefinition的Set集合。
Spring扫描底层流程:
- 首先,通过ResourcePatternResolver获得指定包路径下的所有
.class文件(Spring源码中将此文件包装成了Resource对象)
- 遍历每个Resource对象
- 利用MetadataReaderFactory解析Resource对象得到MetadataReader(在Spring源码中MetadataReaderFactory具体的实现类为CachingMetadataReaderFactory,MetadataReader的具体实现类为SimpleMetadataReader)
- 利用MetadataReader进行excludeFilters和includeFilters,以及条件注解@Conditional的筛选(条件注解并不能理解:某个类上是否存在@Conditional注解,如果存在则调用注解中所指定的类的match方法进行匹配,匹配成功则通过筛选,匹配失败则pass掉。)
- 筛选通过后,基于metadataReader生成ScannedGenericBeanDefinition
- 再基于metadataReader判断是不是对应的类是不是接口或抽象类
- 如果筛选通过,那么就表示扫描到了一个Bean,将ScannedGenericBeanDefinition加入结果集
MetadataReader表示类的元数据读取器,主要包含了一个AnnotationMetadata,功能有
- 获取类的名字、
- 获取父类的名字
- 获取所实现的所有接口名
- 获取所有内部类的名字
- 判断是不是抽象类
- 判断是不是接口
- 判断是不是一个注解
- 获取拥有某个注解的方法集合
- 获取类上添加的所有注解信息
- 获取类上添加的所有注解类型集合
值得注意的是,CachingMetadataReaderFactory解析某个.class文件得到MetadataReader对象是利用的ASM技术,并没有加载这个类到JVM。并且,最终得到的ScannedGenericBeanDefinition对象,beanClass属性存储的是当前类的名字,而不是class对象。(beanClass属性的类型是Object,它即可以存储类的名字,也可以存储class对象)
最后,上面是说的通过扫描得到BeanDefinition对象,我们还可以通过直接定义BeanDefinition,或解析spring.xml文件的<bean/>,或者@Bean注解得到BeanDefinition对象。(后续课程会分析@Bean注解是怎么生成BeanDefinition的)。
实例化非懒加载的Bean查看入口finishBeanFactoryInitialization(beanFactory
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
if (isFactoryBean(beanName)) {
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(
(PrivilegedAction<Boolean>) ((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
}
else {
getBean(beanName);
}
}
}
|
第一遍历所有的beanNames,首先此处有一个概念是RootBeanDefinition,获得合并后的bean定义
合并BeanDefinition
通过扫描得到所有BeanDefinition之后,就可以根据BeanDefinition创建Bean对象了,但是在Spring中支持父子BeanDefinition,和Java父子类类似,但是完全不是一回事。
父子BeanDefinition实际用的比较少,使用是这样的,比如:
1
2
| <bean id="parent" class="com.sunfy.service.Parent" scope="prototype"/>
<bean id="child" class="com.sunfy.service.Child"/>
|
这么定义的情况下,child是单例Bean。
1
2
| <bean id="parent" class="com.sunfy.service.Parent" scope="prototype"/>
<bean id="child" class="com.sunfy.service.Child" parent="parent"/>
|
但是这么定义的情况下,child就是原型Bean了。
因为child的父BeanDefinition是parent,所以会继承parent上所定义的scope属性。
而在根据child来生成Bean对象之前,需要进行BeanDefinition的合并,得到完整的child的BeanDefinition。
再次遍历所有的bean,是否实现了SmartInitializingSingleton接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
if (singletonInstance instanceof SmartInitializingSingleton) {
SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
}
}
|
加载类
BeanDefinition合并之后,就可以去创建Bean对象了,而创建Bean就必须实例化对象,而实例化就必须先加载当前BeanDefinition所对应的class,在AbstractAutowireCapableBeanFactory类的createBean()方法中,一开始就会调用:
1
| Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
|
这行代码就是去加载类,该方法是这么实现的:
1
2
3
4
5
6
7
8
9
10
11
12
13
| if (mbd.hasBeanClass()) {
return mbd.getBeanClass();
}
if (System.getSecurityManager() != null) {
return AccessController.doPrivileged((PrivilegedExceptionAction<Class<?>>) () ->
doResolveBeanClass(mbd, typesToMatch), getAccessControlContext());
}
else {
return doResolveBeanClass(mbd, typesToMatch);
}
public boolean hasBeanClass() {
return (this.beanClass instanceof Class);
}
|
如果beanClass属性的类型是Class,那么就直接返回,如果不是,则会根据类名进行加载(doResolveBeanClass方法所做的事情)
会利用BeanFactory所设置的类加载器来加载类,如果没有设置,则默认使用ClassUtils.getDefaultClassLoader()所返回的类加载器来加载。
ClassUtils.getDefaultClassLoader()
- 优先返回当前线程中的ClassLoader
- 线程中类加载器为null的情况下,返回ClassUtils类的类加载器
- 如果ClassUtils类的类加载器为空,那么则表示是Bootstrap类加载器加载的ClassUtils类,那么则返回系统类加载器
{kind=link}
Copyright 2021 sunfy.top ALL Rights Reserved